Bonsoir,
Presque le week end...
Alors qu'allons nous faire avec cette table de plus de 100 millions de lignes, sachant qu'en général quand on parle de Datawarehouse on parle de plusieurs centaines millions de lignes et rarement d'une seule table !
Vous vous souvenez de la requête:
SELECT id_pays,COUNT(*) FROM Reponse_1
WHERE ((q1=10 AND q2=10 AND q3=10) OR (q1=0 AND q2=0 AND q3=0)) AND (q4=5 AND q5=5 AND q6=5)
GROUP BY id_pays;
1er hypothèse: Je pars du principe que les indexes ne servent à rien (j'en connais qui pensent ca) et je lance ma requête.
Bien evidemment, comme j'ai lu "Performance (2) - Autotrace", je pense à activer cette foncionnalité.
SET AUTOTRACE ON
Le résultat est prévisible, un scan complet de la table.
Les statistiques données (AUTOTRACE) nous indiquent plus de
700000 consistents gets ainsi que
730000 lectures physiques pour une durée de l'ordre de
40 secondes. Autant dire que ce n'est pas acceptable. Un DW, est fait pour être interrogé et pas avec une seule requete par une seule personne.
2ème hypothèse. Dans notre cas, on pourrait alors poser un index par question (q1,q2....q10).
Ca nous fait une dizaine d'indexes et ca permet toutes les combinaisons possibles
Remarque : Les indexes sont crées sur la table Reponse_2 qui est une copie de Reponse_1
Create index idx_q1_r2 on reponse_2(q1);
Create index idx_q2_r2 on reponse_2(q2);
Create index idx_q3_r2 on reponse_2(q3);
Create index idx_q4_r2 on reponse_2(q4);
Create index idx_q5_r2 on reponse_2(q5);
Create index idx_q6_r2 on reponse_2(q6);
Create index idx_q7_r2 on reponse_2(q7);
Create index idx_q8_r2 on reponse_2(q8);
Create index idx_q9_r2 on reponse_2(q9);
Create index idx_q10_r2 on reponse_2(q10);
Faut compter quelques minutes par indexes ... et auxquelles il faut ajouter quelques GO... supplémentaires.
Et pour être plus précis, il faut 1,7 GO par index multiplié par 10 ce qui nous fait 17 GO d'indexes.
Voyons au moins si le jeu en vaut la chandelle.
Paradoxalement les statistiques nous indiquent une baisse conséquente des consistent gets (
174000) ainsi que des lectures physiques (
189000) le temps de'execution est passé lui d'une quarentaine de secondes à presque
deux minutes ! les statistiques nous indiquent également qu'il y a eu quelques 1000 appels recursifs (certainement des appels systemes[mais pour quoi faire ?].
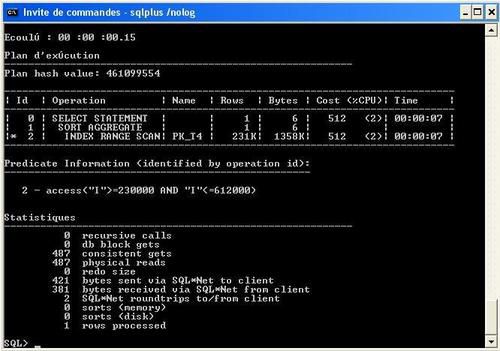
Le plan d'execution nous montre que nos indexes sont bien utilisés.

Alors que faire ? Gacher 17 GO d'index pour un résultat qui devrait être meilleur mais qui ne l'est pas !
Ce qui coute en temps ce sont les "appels récursives" qui sont certainement des appels systemes.
Mais pourquoi faire ?
Le plan d'execution nous indique bien que les indexes sont utilisés, mais qu'ORACLE effectue une conversion des ROWID en BITMAP !
Du sex dans ORacle ? Non mais un type d'index : Les index bitmap !
3 ème hypothèse. Si oracle décide de faire une conversion de type bitmap, peut être avons nous interet à créer directement des indexes de type bitmap.
Qu'est ce qu'un index bitmap ? : ex: Créeons un index bitmap sur q1.
CREATE BITMAP INDEX idx_q1_r1 ON Reponse_1(q1);
1ere constation : La création est beaucoup plus rapide que pour un index classique.
Comme ca marche ?
Q1 peut prendre 11 valeurs (de 0 à 10). Oracle va alors créer un tableau de valeur de 0 à 10 et pour chaque rowid (numéro de sécu d'une ligne dans la table, et accés direct à l'info) va indiquer par 0 ou 1 pour chaque valeur. On peut représenter cela par un tableau. Admettons que pour les premières lignes de la tables, les notes à q1 soient 2,3,4,0,0,1,5,8,9,1,6...
| | 2 | 3 | 4 | 0 | 0 | 1 | 5 | 8 | 9 | 1 | 6 |
| 0 | 0 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 1 | 0 |
| 2 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 3 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 4 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 5 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 |
| 6 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
| 7 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 8 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 |
| 9 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 |
Une suite de 1 er 0 pour définir mon index !!! du binaire ! C'est pas beau.
Beau je ne sais pas, mais efficace certainement.
2ème constatation: la taille de mon index est de l'ordre de 150 MO soit 10 fois moins important qu'un index normal.
Crééons donc tous nous index. (on travaille sur la table Reponse_1)
Create bitmap index idx_q1_r1 on reponse_1(q1);
Create bitmap index idx_q2_r1 on reponse_1(q2);
Create bitmap index idx_q3_r1 on reponse_1(q3);
Create bitmap index idx_q4_r1 on reponse_1(q4);
Create bitmap index idx_q5_r1 on reponse_1(q5);
Create bitmap index idx_q6_r1 on reponse_1(q6);
Create bitmap index idx_q7_r1 on reponse_1(q7);
Create bitmap index idx_q8_r1 on reponse_1(q8);
Create bitmap index idx_q9_r1 on reponse_1(q9);
Create bitmap index idx_q10_r1 on reponse_1(q10);
à peine 1,5 GO pour les dix indexes. Même pas la taille d'un index sur la table Reponse_2.
Reste à esperer qu'en plus ca améliore les performances.
Rejouons notre requête.
1er appel : 6,5 secondes ! pour uniquement
12431 consistents et
12316 lecture phyisiques. Faut dire que je viens de faire ma première requete sur la table et que la base vient de démarrer. Ce qui est rarement le cas en production.
2ème appel:
moins d'une seconde !!!!!! et 12324 consistents gets pour 0 accès disque ! Pour info, dans les deux hypothèses précédentes j'avais également fait plusieurs appels ! mais vu la taille des indexes cela ne pouvait rester en mémoire d'ou les accès disques.
Ma base est configuré avec une SGA de 512 MO et une PGA de 100 MO
J'en vois venir qui vont vouloir coller du BITMAP partout, alors lisez d'abors les lignes qui suivent:
Avertissement: - On ne pose un index bitmap que sur une colonne contenant à nombre réduit de valeurs distinctes ! Typiquement on ne posera pas un index bitmap sur la colonne date_questionnaire sachant que la table va être alimenté tous les mois (voir tous les jours). La documentation ORACLE parle de 300 valeurs pour la limite de valeurs distincte. Moi je dis qu'il faut tester et mesurer (statistiques, taille index,...)
- On pose principalement des indexes bitmap dans des environnement de type datawarehouse ou sur des tables statiques. Imaginons un instant que je décide qu'une question puisse avoit la note de 11 ! à la première insertion avec la valeur 11, ce sont les 115 millions de lignes d'indexes qui vont être mise à jour.
- On préferera créer des index bitmap sur une colonne plutot que des indexes composés.
Conclusion:
C'est beau, c'est pratique et c'est efficace. Mais une question commence à venir, si ma table doit être alimentée tous les jours et qu'un index bitmap est couteux lors des mise à jour, comment allons nous gérer cela ?
Affaire à suivre ....